$\left[0, 1 \right]$ の区間の一様乱数(Uniform-Distributed Random Number, 区間内のどこにも等しい確率で落ちる乱数)を $n$ 個発生させ, その平均値(標本平均)がどのように分布するかを知りたい.多数のデータが足しあわされると, ベル型の正規分布が生じることを調べたいのである.
#!/usr/local/bin/ruby
# add_unif.rb
r = Random.new
n_sampling = 4800
size = 3 #標本の大きさ
n_sampling.times do
sum = 0.0
size.times do
sum += r.rand()
end
puts sum / size
end
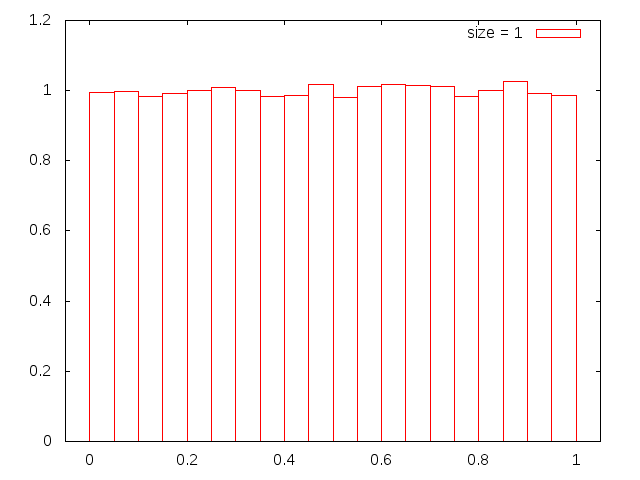
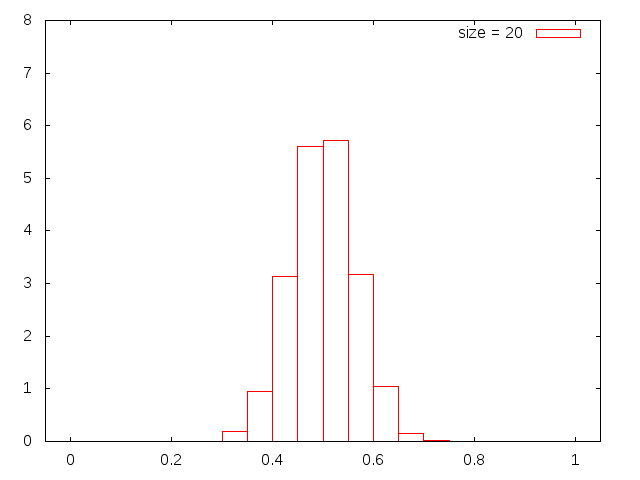
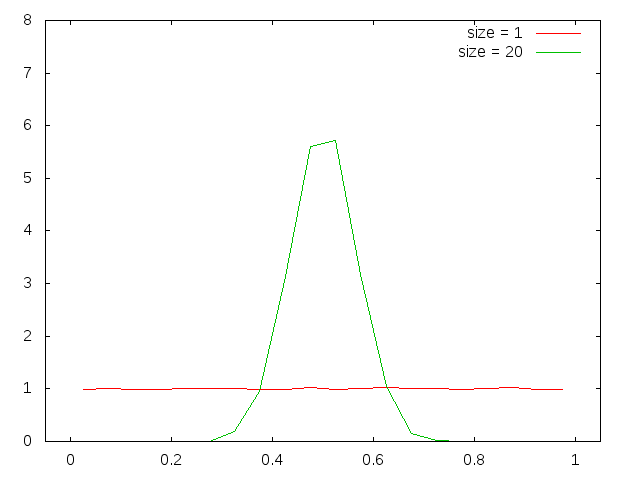
上のプログラムで,標本の大きさsizeを 1 から 20 程度まで変えて実行し, その結果をグラフ化してみよう(最初のグラフのようすがちがったら,こちらを参照).
これらの図を見ると,一見してサイズが小さい時には正規分布とは程遠いことが 分かる.大きいとなんとなく正規分布っぽい. それでは,本当に正規分布になるとしたら,どのへんを境にして正規分布と言えるようになるのだろうか?それを調べていこう.
R にはデータをプロットする機能が豊富に用意されている.ここでは単純な一次元データの分布 をヒストグラムとしてプロットする機能を,手順を追って試してみよう. 今,各行にデータが1個だけ書き込まれているファイルを sample.dat として進めてみる.
DT <- read.table("sample.dat",header=FALSE) # 先頭行からデータが始まるので FALSE 指定
str(DT) # DT の構造を確認して, V1 という名前の数値変数であることをチェック
x <- DT$V1
summary(x) ## データ x の最小値,第一四分位数,中央値,平均,第三四分位数,最大値が表示される
plot(x)
これはわけのわからない図を作り出す. 
library("ggplot2") ## 次の qplot を使うために ggplot2 ライブラリを読み込む
qplot(x,geom="histogram",binwidth=0.05) ## 柱(ビン)の幅を0.05としてヒストグラムを表示
R は1次元データの集合がどのような確率分布に従っているのかを テスト(検定)する機能がそなわっている.下にそれらを箇条書きにして示してある. ここで使いたいのは,正規分布のテストに使われるシャピロ・ウィルク検定だ.
GNUPLOT やR を使ってヒストグラムを描くだけで, 分布が正規分布に近いかどうかの判断がある程度できる.
最初のシミュレーションに戻って,連続一様分布に従うデータの平均が 正規分布とみなせるかどうかを調べたい. 上述のようにシャピロ・ウィルク検定が使える. R による上の作業で x を得たあと,次のようにすればよい.
shapiro.test(x)
この結果,p値としてたとえば 0.1 より小さい値になったら,x は危険率 0.1 で正規分布と有意な違いはないという仮説は棄却される(この言明の仕方に注意して,勘違いしないようににすること).
size = 1 の図が下のようになる人が多いはず.「あれ?一様分布のはずなのに ぜんぜんバラバラじゃない!!」と感じるようなら,君はえらい. そしたら GNUPLOT の設定を工夫しよう. よくやらかしてしまうことなので,グラフを見るときには縦軸と横軸の数値や単位に気をつけること.
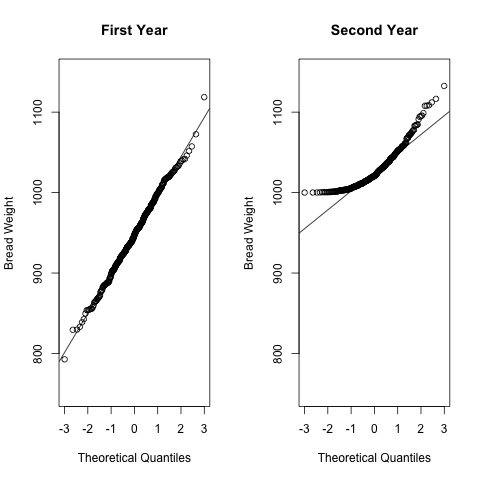
Q-Q プロットというのは,与えられたデータ集合の各分位点の位置と,そのデータと同じ平均,分散を持つ生正規分布の分位点とを縦軸横軸にプロットしたものである.もしもデータが正規分布していれば, プロットは直線になるし,そうでないと歪むことになる.
#!/usr/bin/env Rscript
library(MASS) # MASS ライブラリを使う
P <- read.table("sample.dat",header=F)
str(P) # P がどんな名前と型の変数を持っているか調べる(V1 で numericのはず)
x <- as.numeric(as.character(P$V1))
png("NdistCheck.png")
qqnorm(y1,main = "Main Title",ylab="hogehoge",ylim=c(750,1150))
qqline(y1)
ポアンカレはフランスの天才数学者の1人であり,「ポアンカレ予想」という難問を後世に贈って,現代に至るまで数学者たちをきりきりまいさせた
ことで名前を知られている.彼にはこんな逸話がのこされている.ただし後世の作り話らしい.
ポアンカレは,地方に単身赴任しているとき,毎日買ってきたパンの重量を
量って記録をとっていた. 着任から1年後,彼はそのデータを持って警察に出向き,
パン屋を告発した.ポアンカレによると,1000g という表示のパンの重さの平均値は
950 g しかなかったというのである.その結果,パン屋は警察に呼ばれて絞られるはめになった.
その1件以来,ポアンカレに渡されるパンはすべて 1000 g以上のものばかりになった. しかし,ふたたび1年後,ポアンカレはデータを手に警察に出向き,パン屋を告発した. 確かにパンは 1000 g 以上だったのだが,その分布をみるとパン屋が作っているパンは 前と同じものであるにも関わらず,その中から 1000 g 以上のものだけをポアンカレに売っていたことが,重量の分布から明らかだったからである.
Shapiro-Wilk normality test data: y1 W = 0.9974, p-value = 0.8303 Shapiro-Wilk normality test data: y2 W = 0.8833, p-value = 4.959e-16