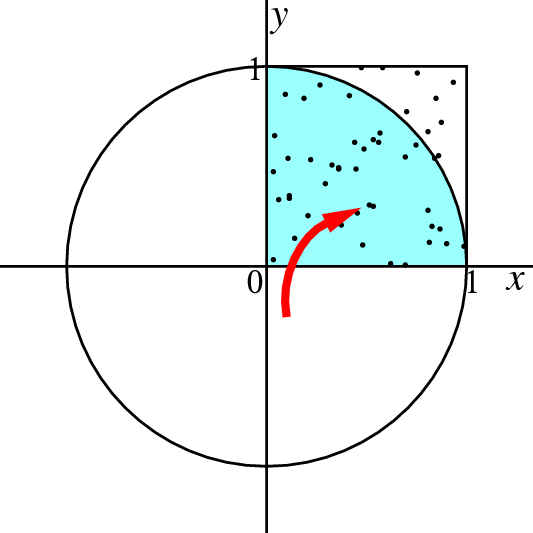
円周率をモンテカルロ法で求める問題では, 図の正方形の部分に一様乱数をランダムに打ち込んだ場合, 円弧の中に入る確率は$p = \pi/4 (= 0.7853981633974483\ldots) $になる。 打ち込んだ乱数の数を $n$, 入った数を $x$ とすると, 円周率 $\pi$の近似値として $4x/n$ をとればよいことは,ちょっと計算してみればわかるだろう。
打ち込む乱数の数は,0から1までの間にある無数の実数からランダムに選んでくる数だ。 統計学の用語を使えば, これは無作為標本抽出における標本の大きさ(サイズ)に相当することに注意しておく。 さて, 十分に多数の乱数を使えば精度よく円周率が求まるだろうというのは自然な考えだ。 それでは,どれくらい多数にすれば,どれくらい精度が高まるのだろうか? それを知っておかないと,結果に自信をもつことはできないよね。
確率論から $x$の分布は二項分布になることがわかり,さらに $x$ の 期待値は $\mu = np$,標準偏差は $\sigma = \sqrt{np(1-p)}$ である。 この標準偏差から,精度を求めることができる。
標準偏差は $x$ の広がりの幅を決めるパラメータだ。$n$ が大きければ $x$ の分布は 正規分布とみなせるので,正規分布表や 正規分布のパーセント点を参照すれば,99% の乱数が円弧に入る範囲を見積もることができる. 実際,$x$が平均値を中心にして $\pm 2.576 \sigma$ の範囲に入ることが,表から分かる。 上に述べたように, $x$ に $4/n$を掛ければ $\pi$の推定値がえられるから, $4x/n$ の値の 99%が入る範囲の幅は次のようになる。
\[ \pm 2.576 \sigma \times \frac4n = \frac{\pm 4\times2.576\sqrt{np(1-p)} }{n} = \frac{\pm4.230}{\sqrt{n}} \]一方,分布の中央は \[ \mu \times \frac4n = 4p \] であるから,結局 $4x/n$の値は次の区間内に 99% の確率で集まることになる。 \[ \left[ 4p - \frac{4.230}{\sqrt{n}}, 4p + \frac{4.230}{\sqrt{n}} \right] \]
それでは,モンテカルロ法で得られる $\pi$ の値の分布を調べるための実験を行っていくことにしよう。高速で実行できるCのプログラムと,テキストやファイルの扱いに優れた Ruby のスクリプト を併用すると効率がよい。
Cのプログラムの名前は calcPi2.c,それをコンパイルした実行プログラムは calcPi2 とする(このページの末尾にソースがある)。ただし Windows の場合,バイナリの実行プログラムの拡張子は .exe とすることになっているので, calcPi2.exeになる。このプログラムは, コマンドライン引数で 「打ち込む」乱数の個数(統計学的には「標本の大きさ」である)(ここでは 10000)を与えて実行する。すると瞬時に$\pi$の推定値の計算結果 が標準出力に返される。
> ./calcPi2 10000 3.157600000標本の大きさを適当に設定して, 何度も実行してみると,バラバラだが円周率に近い数値がそのたびに現れる。 これをたとえば 1000回やって,たくさんの推定値を集める。 推定値はランダムに見えるが,ある分布に従うことが分かる。 次に標本の大きさを変えてみて,同じことをやってみる。 このようにして, 標本の大きさによって推定値の分布がどのように変わるかを調べ,理論値と比較してみようというのが,この実験の流れである。
標本の大きさ(打ち込まれる乱数の個数)を sample_sizeとする。 分布を調べるためには,繰り返し$\pi$を求めるプログラムを走らせて, 出力される結果を集めることが必要だ。
繰り返される試行の数をn_trial とすると,全体としては次のように進めればよいことになる。これを実行する Ruby のプログラムを作りなさい。
# n_trial を決める(統計検定に使うなら100,ヒストグラムを描くには1000〜10000)
# 標本の大きさを変えながら計算させたいので, 100, 10000,... 100000000 程度まで配列 sample_sizes に入れる
# sample_sizes から each メソッドで要素を取り出して sample_size へ
# sample_size を含むログファイル名を作成。 "log1000.dat" などのように
# 空のログファイルを生成
# n_trial 回,次の形で繰り返す ">>" は追加モードでリダイレクトする
# system("calcPi2 1000 >> log1000.dat")
# 終了後,log100.dat などに結果が書き込まれているので,次の分析に移る
上記の処理は莫大な回数の計算が必要なので,かなり時間がかかる。標本の大きさと試行の回数を調節して,待ちきれる時間内に終わるようにすること。
UNIX の time コマンドを使うと,次のように処理にかかる時間を計測することができる。
> time calcPi2 100000出力された時間から計算して,適切な計算回数を設定するようにしよう。プログラムが「行ってしまっていつ戻るかわからない。ひょっとしたらお亡くなりに???」ということになると,結構やきもきする。
以上のようにして得られたデータの形は,次のように$\pi$の近似値の集合になっている。
3.137400000 3.140480000 3.140600000 3.136640000 3.141160000 3.139720000 3.145160000 3.137400000 3.134040000 3.136240000 ... ...このデータについて,どのような分析が可能だろうか。
1は,すでに紹介した mkfreqtbl2.rb を使って 度数分布表のデータを作成して,それを GNUPLOT で可視化する。
2 は,簡単な Ruby のプログラムを使って条件に合致するデータを数え,その比率を求める。
3,4,5 は R を使うと便利である。R のデータフレームにデータを読み込んで, summary 関数を
次のプログラムは,すでに紹介したプログラムから,処理時間の出力を省いて,$\pi$ の推定値だけを出力するようにしたものである。
// calcPi2.c
/*
モンテカルロ法を使って円周率を求める.
乱数生成には優れた擬似乱数を高速に発生するメルセンヌツイスタのアルゴリズ
ムを用いる.詳しい情報は同梱の MT.h のコメントを見よ.
コンパイルは次のようにする
gcc calcPi2.c -lm -O3 -o calcPi2
オプションの意味:
-lm : 数学ライブラリをリンク
-O3 : できる限りの最適化を行って高速にする
-o : 生成する実行ファイルの名前を指定
実行するときには次のようにコマンドライン引数で標本の大きさを与える
./calcPi2 1000
*/
#include <stdio.h>
#include <math.h>
#include <time.h>
#include <limits.h>
#include "MT.h"
int main(int argc, char *argv[]){
long i, n_trial, hit = 0;
double x,y;
// 精密な時刻データを使って種を蒔く
init_genrand((unsigned)(clock() * UINT_MAX) % ULONG_MAX);
n_trial = atol(argv[1]);
for(i=0;i < n_trial;i++){
x = genrand_real1();
y = genrand_real1();
if(y < sqrt(1.0-x*x))
hit ++;
}
printf("%12.9f\n",4.0*hit/(double)n_trial);
return 0;
}